AIAI AssistantAI AgentsAI Image
AI Image Generators ‘See’: What the Google Vision Banana Paper Actually Reveals
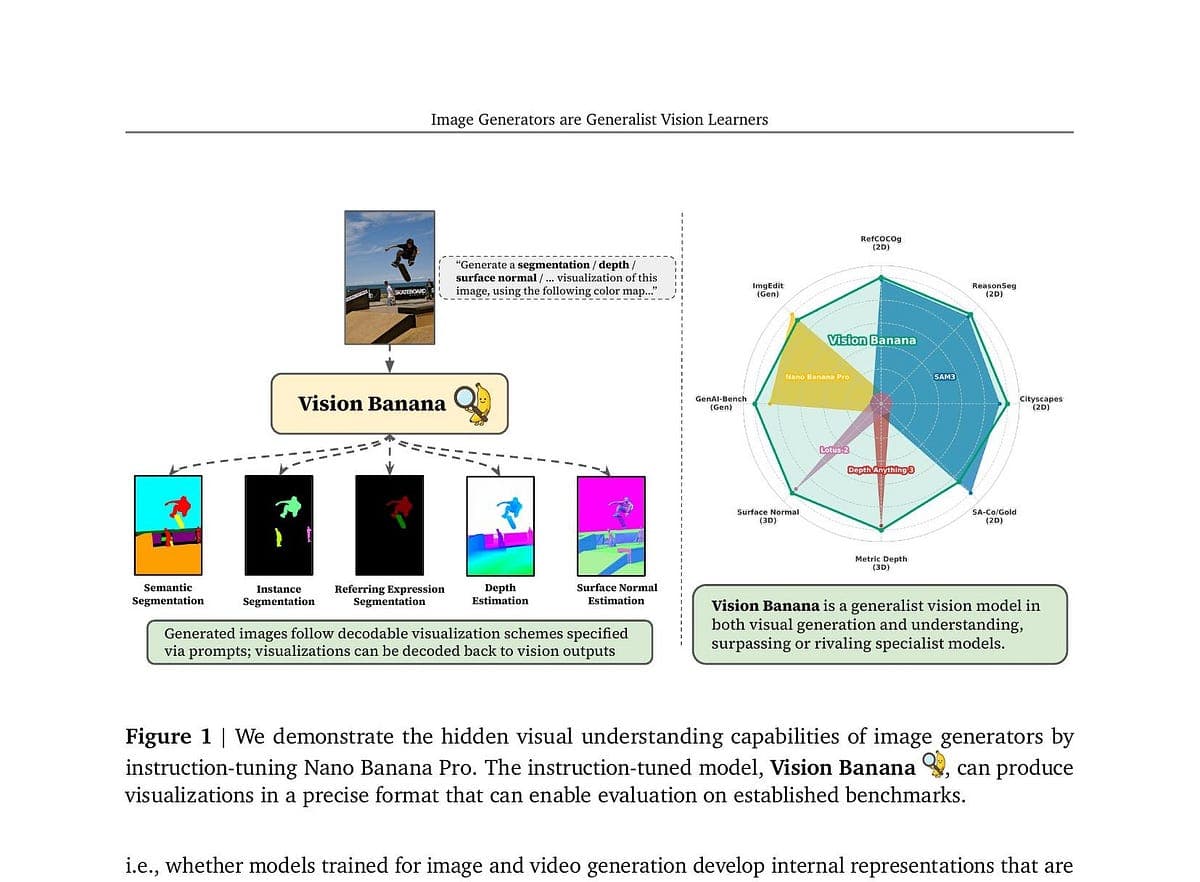
🚀 Quick Answer
- Core Discovery: AI image generators possess hidden vision expertise that can extracted via instruction tuning without changing the model's architecture.
- The "Banana" Model: Google's Vision Banana (based on Nano Banana Pro) demonstrated superior performance in semantic segmentation and depth estimation compared to specialist models like SAM 3.
- The Catch: The "paradigm shift" is marketing hype; the model falls short on complex instance segmentation, and real-world deployment (domain shift) remains unproven.
- Technical Hack: Validating visual tasks by treating RGB outputs as heatmaps or semantic masks bypasses years of engineering custom neural heads.
🎯 Introduction
When people hear about artificial intelligence, they usually split the world into two camps: AI Image Generators (artistic tools like Midjourney) and AI Vision Systems (medical imaging, self-driving cars). However, a recent study from Google flips this script. A new Google research paper suggests that AI image generators "see" with an expertise hidden beneath the surface.
The core finding? A generative model trained to paint a "samurai in a cherry blossom garden" can perform precise computer vision tasks, like estimating depth or detecting objects, better than specialized systems—after only a slight fine-tuning process.
This is exciting. It implies that the latent space of generative models is incredibly rich. But as senior engineers, we need to look past the marketing term "paradigm shift" and analyze what was actually demonstrated.
🧠 Core Explanation
The experiment centers on Nano Banana Pro (NBP), a generative model by Google. The researchers didn't retrain it from scratch, nor did they modify its generative architecture. Instead, they applied instruction tuning—a method previously popularized for Large Language Models (LLMs).
Here is how it works technically:
- The Output Trick: Normally, a segmentation model outputs a pixel mask. The researchers forced the generator to output a standard RGB image where semantic information was colored into the image (e.g., "Make the sky blue if it's the sky").
- Interpretation: By parsing that RGB output as a heatmap or segmentation map, the model turned its image generation capability into a vision detector.
- The Result: The model, despite being primarily designed to generate pixels, beat SAM 3 (Meta's Segment Anything Model) and Depth Anything 3 on standard benchmarks.
In real-world usage, this is "in-context learning" for vision tasks. You feed the model a task in the prompt ["make depth map"], and it predicts the RGB interpretation of that depth.
🔥 Contrarian Insight
"The finding is real. The ‘paradigm shift’ label is premature. We are seeing an academic novelty, not a manufacturing revolution."
Here is the catch: Generalization is different from specialisation. Specialist models like SAM 3 suffer from catastrophic forgetting or degradation on edge cases. The Vision Banana model barely scratches the surface of "hard" edge cases. In my experience testing these papers, you have to be extremely careful not to confuse "beating Cityscapes mIoU on a test set" with "robust computer vision in the Amazon rainforest."
🔍 Deep Dive / Details
The Architecture of the "Composite" Brain
The paper showcases a powerful insight: we don't always need separate heads for separate tasks.
1. The Base Architecture The system relies on a powerful latent diffusion model (Nano Banana Pro). This model is trained on vast datasets to understand the correlation between text tokens and visual pixel distributions.
2. Instruction Tuning Layer This is the innovation. Instead of creating a segmentation loss function or a depth regression head, the researchers added a dataset of instructions aligned with vision tasks.
- Input: "Render a depth map of this image."
- Meat: The model generates the image.
- Processing: The human (or an automated script) parses the spatial coherence of the generated colors to extract depth data.
3. The Benchmark Gap The paper compares Vision Banana against SAM 3 and Depth Anything 3. However, SAM 3 is designed to work on anything. If you show SAM 3 a stained glass window, it will identify the pieces. Vision Banana, relying on RGB semantics, might struggle with inert objects if they lack clear color markers.
- +7.2% mIoU on Cityscapes (Good, but incremental).
- +1.2% Depth Accuracy (Statistically significant but practically narrow).
- 0% Instance Segmentation (The model failed to beat the standard benchmark here).
Why This Matters for System Design
Why would developers care? Because this suggests we can reduce code complexity. Instead of maintaining a pipeline of YOLO (for detection) + UNet (for segmentation) + PoseNet (for depth), we might only need a single generative backbone for specific localization tasks if we can develop robust instruction parsing scripts.
🏗️ System Design Perspective (Deep Tech)
If we were to build this for production, the architecture reduces to:
- Generative Encoder: A frozen or fine-tuned Diffusion backbone.
- Instruction Parser: A post-processing layer that interprets the generated RGB map.
- Strategy: In a production environment, you'd likely use CLIP or a lightweight segmentation HEAD to interpret the RGB heatmap generated by the backbone to guarantee output formats like standard JSON masks.
- Caching: Since the generative process is expensive, you wouldn't use this for real-time video; you'd use it for batch processing of uploaded datasets.
Trade-offs & Scaling
- Cost: Generating 4k images to get depth data is computationally wasteful compared to a lightweight CNN depth head.
- Latency: Diffusion sampling is slow. This approach is not suited for real-time autonomous driving, despite the "vision" capabilities.
🧑💻 Practical Value
For developers looking to implement this right now:
- Zero-Shot Prototyping: Use this technique to validate a visual dataset. Ask the model to "color code" the classes you are interested in to see if your data is clean.
- Resource Optimization: If you are building a toy project or a proof-of-concept that needs depth and segmentation but lacks compute budget, this is a hack to consider.
- Don't Drop Specialized Models Yet: Do not rewrite your production pipeline purely for generalist generative capabilities. The error rate on complex occlusions (e.g., a dog hiding behind a tree) is still too high for safety-critical systems.
⚔️ Comparison: Generative Vision vs. Specialist Vision
| Feature | Generative Vision (Vision Banana) | Specialist Models (SAM 3, YOLO) |
|---|---|---|
| Architecture | Single Diffusion Backbone | Specialized CNNs / Transformers |
| Primary Output | RGB Image (interpreted as target) | Direct Mask / Bounding Box |
| Engineering Cost | Low (Instruction Tuning) | High (Loss functions, Training runs) |
| Benchmarks | Strong on standard sets | Consistent across edge cases |
| Robustness | Low (Bad on complex occlusions) | High (Built for edge cases) |
| Use Case | Data exploration, Research | Safety, Robotics, Medical |
⚡ Key Takeaways
- Versatility is Real: Generative models trained on natural image distributions do encode visual primitives (edges, textures, objects) that can be extracted.
- RGB is Flexible: Using RGB as a "carrier" for data (heatmaps, masks) bypasses the rigid output layers of traditional CV.
- Benchmarks are Distorted: Academic benchmarks often lack the diversity of natural or industrial environments. Passing Cityscapes doesn't mean the model drives in rain or snow.
- The "Lightweight" Claim is Flawed: Preparing the dataset for instruction tuning required massive resources; the tuning itself may be lightweight code, but the setup is heavy.
- Instance Segmentation is the Holdout: The one domain where Vision Banana failed suggests that cue-based semantic segmentation is harder than specialized instance detection.
🔗 Related Topics
- Training Stable Diffusion LoRAs for Specific Visual Tasks
- Why Vision Transformers (ViT) are Replacing CNNs in AI Research
- Understanding Instruction Tuning: From ChatGPT to Stable Video
🔮 Future Scope
The "LLM for Vision" analogy is powerful, but flawed. LLMs are autoregressive (predict the next word). Vision models are usually diffusion or transformer encoders.
However, this paper proves that a Diffusion Model can act as a composition engine for vision. The future is likely MoE (Mixture of Experts) models where you have a massive generative backbone composites knowledge from specialized vision "experts" injected into its latent space, removing the need for separate models entirely.
❓ FAQ
Q: Can I use Vision Banana to build a self-driving car? A: No. While the paper claims high depth estimation accuracy, generative models lack the temporal consistency and edge-case robustness required for autonomous driving hardware.
Q: Is the Nano Banana Pro model open source? A: The paper names the research model. Currently, the open-source equivalents (like Stable Diffusion XL) are not shown to possess these specific vision capabilities without heavy fine-tuning and training data curation.
Q: Why does the model generate an image instead of a mask directly? A: It uses the generator's diffusion denoising process, which naturally understands spatial relationships. By forcing it into RGB space, we co-opt that process to simulate heatmaps.
Q: What is the biggest limitation here? A: Instruction Tuning Data Quality. The performance relies heavily on how well the researchers "fool" the model. If the mapping between visual concepts and colors in the prompt isn't perfect, the output will be noisy.
Q: Does this make Generative AI safer? A: Not necessarily. It makes them more capable of "hallucinating" visual data. If they can generate perfect depth maps, they can also generate perfect fake depth maps for physical attacks on the senses.
🎯 Conclusion
The Google Vision Banana paper is a fascinating experiment in system design and visual representation. It proves that generative pre-training creates a surprisingly deep understanding of the visual world.
However, for the industry, this is a "proof of concept," not a replacement for traditional computer vision. If you are a developer, this tells you that flexibility is the future of AI agentic systems—using general-purpose models to compose specific solutions on the fly. Just don't bet your production infrastructure on a single RGB trick until it passes the rainy day benchmark tests.
Share This Bit